什么是 Crawl Frontier?¶
Frontera 一个实现 crawl frontier 的框架。crawler frontier 是爬虫系统的一部分,它决定了爬虫抓取网页时候的逻辑和策略(哪些页面应该被抓取,优先级和排序,页面被重新抓取的频率等)。
通常的 crawl frontier 方案是:
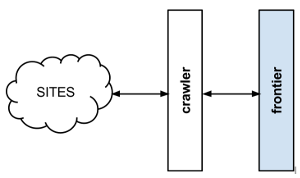
frontier 以 URL 列表初始化,我们称之为种子。 一旦边界初始化,爬虫程序会询问下一步应该访问哪些页面。 当爬虫开始访问页面并获取结果时,它将通知 frontier 每个页面响应以及页面中包含的超链接。 这些链接被 frontier 当做新的请求加入,安装抓取策略进行抓取。
这个过程(请求新的任务/通知结果)会一直重复直到达到爬虫的结束条件。一些爬虫可能不会停止,我们称之为永久爬虫。
Frontier 抓取策略几乎可以基于任何的逻辑。常见情况是基于得分/优先级,它们通过一个或多个页面的属性(新鲜度,更新时间,某些条款的内容相关性等)计算得来。也可以基于很简单的逻辑,比如 FIFO/LIFO 或 DFS/BFS 。
根据 frontier 的逻辑,可能需要持久存储系统来存储,更新或查询页面信息。 其他系统可能是100%不稳定的,并且不会在不同爬虫之间共享任何信息。
更多 crawl frontier 理论请参照 Christopher D. Manning, Prabhakar Raghavan & Hinrich Schütze 写的 URL frontier 文章。