运行模式¶
下图展示了运行模式的架构图:
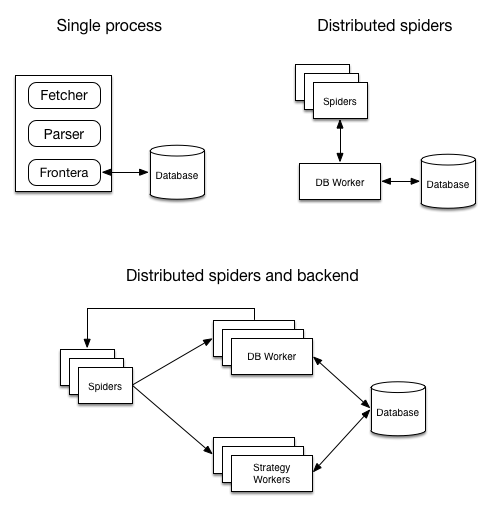
单进程¶
Frontera 与 fetcher 在相同的过程中实例化(例如在 Scrapy 中)。要实现这个,需要设置 BACKEND 为 Backend 的子类。这种模式适合那种少量文档并且时间要求不紧的应用。
分布式爬虫¶
爬虫是分布式的,但后端不是。后端运行在 db worker 中,并通过 message bus 与爬虫通信。
- 将爬虫进程中的
BACKEND设置为MessageBusBackend - 在 DB worker 中
BACKEND应该指向Backend的子类。 - 每个爬虫进程应该有它自己的
SPIDER_PARTITION_ID,值为从0到SPIDER_FEED_PARTITIONS。 - 爬虫和 DB worker 都应该将
MESSAGE_BUS设置为你选择的消息总线类或者其他你自定义的实现。
此模式适用于需要快速获取文档,同时文档的数量相对较小的应用。
分布式爬虫和后端¶
爬虫和后端都是分布式的。后端分成了两部分: strategy worker 和 db worker。strategy worker 实例被分配给他们自己的 spider log 部分。
- 将爬虫进程中的
BACKEND设置为MessageBusBackend - DB workers 和 SW workers 的
BACKEND应该指向DistributedBackend的子类。同时还需要配置您选择的后端。 - 每个爬虫进程应该有它自己的
SPIDER_PARTITION_ID,值为从0到SPIDER_FEED_PARTITIONS。最后一个必须可以被所有 DB worker 实例访问。 - 每个 SW worker 应该有自己的
SCORING_PARTITION_ID,值为从0到SPIDER_LOG_PARTITIONS。最后一个必须可以被所有 SW worker 实例访问。 - 爬虫和所有的 worker 都应该将
MESSAGE_BUS设置为你选择的消息总线类或者其他你自定义的实现。
在这种模式下,只有 Kafka 消息总线、SqlAlchemy 和 Habse 后端是默认支持的。
此模式适用于广度优先抓取和网页数量巨大的情况。