架构概述¶
本文档介绍了Frontera Manager管道,分布式组件以及它们的交互方式。
单进程¶
下图显示了Frontera管道的架构,其组件(由数字引用)和系统内发生的数据流的轮廓。 有关组件的简要说明,请参见以下有关它们的更多详细信息的链接。 数据流也在下面描述。
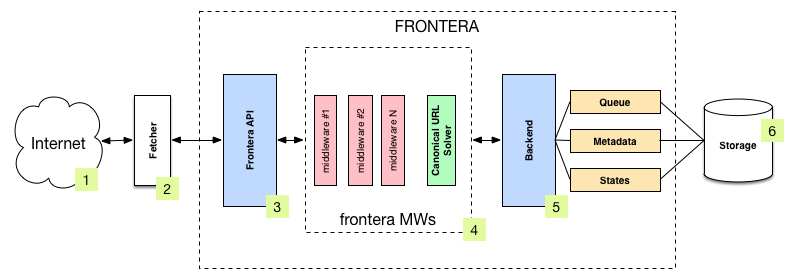
组件¶
Fetcher¶
Fetcher(2)负责从网站(1)中获取网页,并将其提供给管理接下来要抓取哪些页面的 frontier。
Fetcher 可以使用 Scrapy 或任何其他爬虫框架/系统来实现,因为框架提供了通用的 frontier 功能。
在分布式运行模式下,Fetcher由Frontera Manager侧的消息总线生产者和Fetcher侧的消费者替代。
Frontera API / Manager¶
Frontera API(3)的主要入口点是 FrontierManager 对象。Frontier 用户(在我们的案例中是Fetcher(2))将通过它与 Frontier 进行通信。
更多请参考 Frontera API 。
Middlewares¶
Frontier middlewares (4) 是位于Manager(3)和Backend(5)之间的特定钩子。 这些中间件在传入和传出 Frontier 和 Backend 时处理 Request 和 Response 对象。 它们通过插入自定义代码提供了一种方便的扩展功能的机制。 规范URL解算器是一种特殊的中间件,负责替代非规范文档URL。
更改请参考 Middlewares(中间件) 和 内置规范 URL 解算器参考 。
数据流¶
Frontera 的数据流由 Frontier Manager 控制,所有数据都通过 manager-middlewares-backend 流程,如下所示:
- frontier初始化为种子请求列表(种子URL)作为爬虫的入口点。
- fetcher请求一批任务去抓取。
- 每个url都被提取,并且 frontier 被通知回传抓取结果以及页面包含的提取数据。 如果在爬行中出现问题,frontier 也会被通知。
一旦所有 url 被抓取,重复步骤2-3,直到达到 frontier 结束条件。每个循环(步骤2-3)重复被称为 frontier 迭代 。
分布式¶
在分布式模式下运行时,所有 Frontera 进程都使用相同的 Frontera Manager。
整体系统形成一个封闭的圆圈,所有的组件都在无限循环中作为守护进程工作。 有一个 message bus 负责在组件,持久存储和 fetcher(当和提取结合时,fetcher又叫做spider)之间传输消息。 有一个传输和存储层抽象,所以可以插上它自己的实现。 分布式后端运行模式具有三种类型的实例:
- Spiders 或者 fetchers,使用Scrapy(分片)实现。
- 负责解决DNS查询,从互联网获取内容并从内容中进行链接(或其他数据)提取。
- Strategy workers (分片)。
- 运行爬网策略代码:为链接链接,决定链接是否需要被抓取,以及何时停止抓取。
- DB workers (分片)。
- 存储所有元数据,包括分数和内容,并生成新的批量任务以供爬虫下载。
*分片*意味着组件仅消耗分配的分区的消息,例如处理数据流的某些共享。*复制*是组件消耗数据流,而不管分区。
这样的设计允许在线操作。可以更改抓取策略,而无需停止抓取。 爬虫策略 也可以作为单独的模块实现; 包含用于检查爬网停止条件,URL排序和评分模型的逻辑。
Frontera 的设计是对Web友好的,每个主机由不超过一个的爬虫进程下载。这是通过数据流分区实现的。
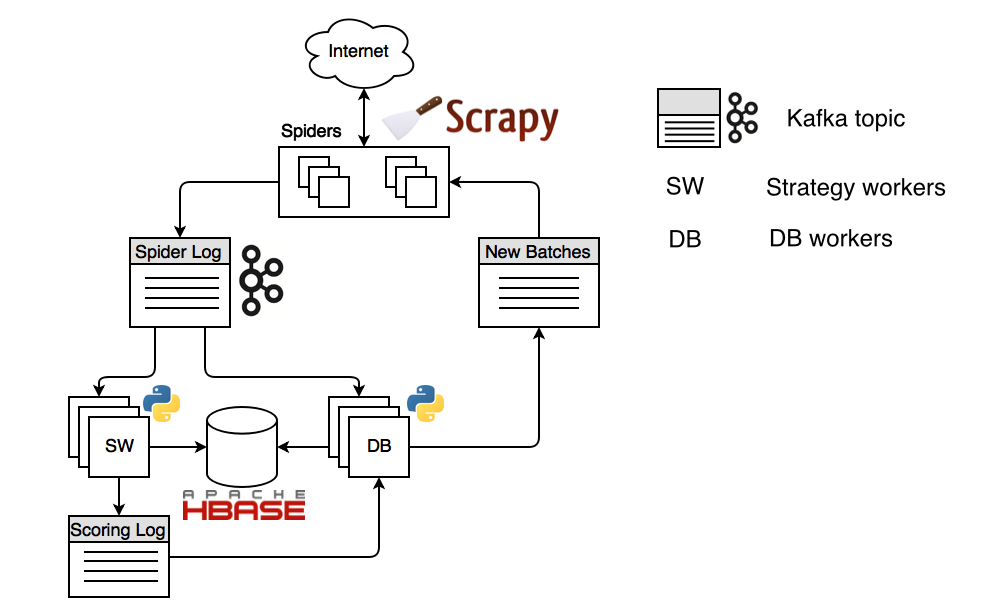
数据流¶
我们从爬虫开始吧。爬虫内的用户定义的种子URL通过 spider log 流发送给 strategy workers 和 DB workers。strategy workers 使用状态缓存决定抓取哪些页面,为每个页面分配一个分数,并将结果发送到 scoring log 流。
DB Worker存储各种元数据,包括内容和分数。另外 DB Worker 检查爬虫消费者的偏移量,并在需要时生成新的任务,并将其发送到 spider feed 流。爬虫消耗这些任务,下载每个页面并从中提取链接。然后将链接发送到 ‘Spider Log’ 流,并将其存储和记分。 这样,流量将无限期地重复。